
Have you ever searched for something online, only to get a flood of irrelevant results? You type “best budget smartphone,” but instead of helpful recommendations, you get pages where “smartphone” and “budget” are mentioned separately, without real context. Traditional search engines rely on full-text keyword matching, which often fails to grasp the true intent behind queries. But what if search could understand what you mean, not just what you type?
That’s where semantic search powered by vector databases comes in. Unlike keyword-based search, semantic search interprets meaning, converting words and phrases into numerical representations called semantic embeddings. This ensures that search results are ranked based on context and relevance, not just keyword presence.
For businesses, this technology isn’t just another AI buzzword—it’s a game-changer:
- E-commerce stores can deliver smarter product recommendations.
- Corporate knowledge bases can provide more precise search results.
- Customer support bots can better understand and respond to queries.
- Users get faster, more intuitive search experiences.
If this sounds complex, don’t worry! We’ll break everything down in simple terms, from how vector databases store and retrieve search data to optimizing semantic search performance.
Ready to master the future of search? Let’s dive in.
Table of contents
- The Evolution of Search: From Keywords to Meaning
- The Role of Vector Databases
- Core Concepts of Semantic Search: How It Works and Why It Matters
- Building Blocks of a Semantic Search System
- How to Cache Semantic Search for Faster and Smarter Results
- Practical Use Cases of Semantic Search and Vector Databases.
- Tips for Implementation: Best Practices for Semantic Search
- Conclusion
The Evolution of Search: From Keywords to Meaning
Search has come a long way from its early days. Back then, finding information meant relying on exact keyword matches. If you searched for “best running shoes for marathon,” traditional search engines would focus only on the words—matching results that contained “running,” “shoes,” and “marathon” but failing to recognize intent.
This led to frustrating experiences where highly relevant results were excluded just because they used slightly different wording. For example, an e-commerce store selling high-performance marathon sneakers might not appear in results if it didn’t include the phrase “best running shoes for marathon”—even if it was the perfect match.
Traditional full-text search prioritizes words over meaning—which is why businesses are now shifting to semantic vector search to deliver more intuitive, intent-driven results.
The Limitations of Full-Text Search
While full-text search has been the foundation of search technology for years, it comes with significant limitations that make it outdated for modern use cases.
- Keyword Dependence: Traditional search relies on exact word matches, meaning slight variations can prevent relevant results from appearing.
Example: Searching for “laptop with good battery” might not retrieve “long-lasting ultrabook”, even though they mean the same thing.
- Word Ambiguity: Some words have multiple meanings, and traditional search engines fail to distinguish between them.
Example: A search for “jaguar” might return results about both the car brand and the animal, without understanding the user’s intent.
- Lack of Context Understanding: Traditional search does not prioritize contextual relevance, which leads to fragmented results. Example: Searching for “comfortable office chair for back pain” may return results for “office chair” and “back pain” separately, instead of prioritizing ergonomic chairs designed for lumbar support.
In short, full-text search focuses too much on words and not enough on meaning, leading to irrelevant or incomplete results. This is where semantic vector search takes over.
The Rise of Semantic Search: Matching Meaning, Not Just Words
Instead of scanning for words, semantic search interprets user intent—understanding what people actually mean when they search.
How Does It Work?
- Uses embedding-based retrieval, where words, sentences, and even entire documents are converted into vector embeddings—numerical representations that store meaning in a high-dimensional space.
- Instead of performing a word-by-word comparison, it retrieves the closest matches based on semantic similarity.
Example:
- The phrase “Best running shoes for marathon” is converted into a vector representation.
- Product descriptions are also stored as vectors in a database.
- The system compares these vectors using cosine similarity or other measures to find the most relevant matches—even if they don’t contain the exact same words.
The Result?
Search becomes more intuitive, natural, and effective—delivering results that match intent, not just keywords.
Vector Databases: The Engine Behind Semantic Search
To store and search millions of vector embeddings efficiently, businesses are moving away from traditional relational databases and adopting vector database semantic search. Unlike conventional databases, vector databases are designed specifically for semantic retrieval—allowing for fast and scalable meaning-based search.
A vector database is built specifically to:
- Store and manage vector embeddings efficiently
- Perform fast searches using approximate nearest neighbor (ANN) algorithms
- Scale to millions (or billions) of vectors without slowing down
Popular solutions include:
- Pinecone: Fully managed, high-speed vector database, great for recommendation systems and semantic search.
- Weaviate: Open-source vector database with hybrid search (combining semantic and keyword search).
- Milvus: High-performance vector database used in AI-powered applications.
- SingleStore: Supports structured and unstructured data, making it useful for enterprise AI workloads.
- Elasticsearch (with vector search enabled): With built-in vector search capabilities, it’s popular for integrating semantic and traditional keyword searches.
Why It Matters: Vector databases power AI-driven search experiences, allowing businesses to deliver faster, more accurate, and context-aware results.
Beyond Words: The Power of Context-Aware Search
Semantic search isn’t just about text—it also enhances image search, voice search, and multilingual search, making AI-powered search systems more accessible and intelligent.
- Multilingual Semantic Search: A search for “affordable hotel near Eiffel Tower” in English can retrieve French-language results—even without English words.
- Retrieval-Augmented Generation (RAG) for Chatbots: Instead of fetching generic FAQs, semantic search enables chatbots to find and summarize the most relevant answer—improving response accuracy.
- Enterprise Knowledge Management: Employees can locate internal reports, documents, and presentations without needing exact file names—enhancing productivity and data accessibility.
The Role of Vector Databases
Imagine you own an online store with thousands of products, each carefully listed with detailed descriptions. One day, a customer searches for “lightweight hiking shoes with ankle support”, hoping to find the perfect fit. But there’s a problem—your product descriptions don’t contain that exact phrase.
A traditional keyword-based search would likely struggle, failing to show relevant results—even though you have the ideal product. The reason? It’s only looking for exact word matches, not understanding what the customer actually means.
This is where semantic vector search steps in, going beyond basic full-text search. But to make this work efficiently, it needs a powerful system to store and retrieve meaning-based data—and that’s exactly what vector databases are built for.
What is a Vector Database?
A vector database works by storing data as numbers instead of plain text, helping AI recognize patterns and relationships based on meaning, not just exact word matches.
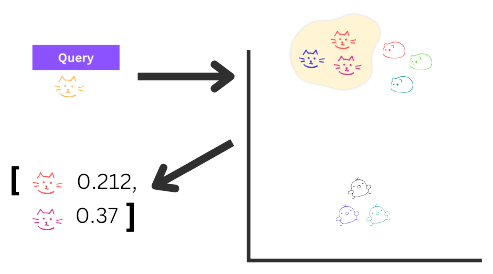
Think of it like a smart salesperson who doesn’t just look for the exact shoes you asked for but suggests similar options based on what you might like. Or like an e-commerce site that recommends products related to your search, even if the wording is different.
This is exactly how AI-driven search, personalized recommendations, and text generation work. Vector databases make it possible for advanced AI applications—like Large Language Models (LLMs)—to understand, connect, and generate meaningful content in a way that feels more natural and intuitive.
Why Do We Need Vector Databases?
A vector database is a special kind of database designed to store and find information based on meaning, not just exact words. Instead of regular text, it saves numerical representations (called vectors) of words, sentences, or even images, making AI-powered search much smarter.
Let’s make it simple.
Traditional databases like SQL and NoSQL are great for handling structured data—things like names, product details, and order IDs. But when it comes to understanding search intent or finding contextually relevant results, they struggle because they aren’t built to process vectors.
That’s where vector databases come in. They are designed for AI-powered search, helping businesses retrieve the most relevant results in real-time—even if the search query doesn’t contain exact words. Whether it’s powering semantic search, personalized recommendations, or AI-generated content, vector databases make everything faster, smarter, and more intuitive.
How Vector Databases Work
Vector databases make AI-powered search smarter by finding meaning-based matches instead of relying on exact words. Here’s how it works in simple terms:
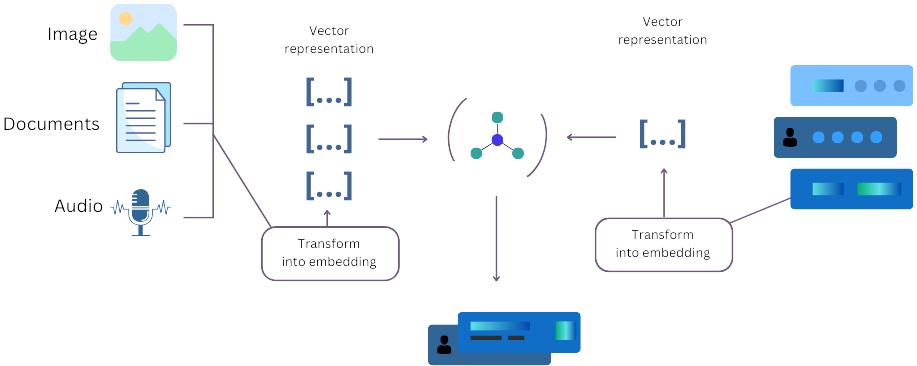
- Step 1: Converting Data into Vectors
Think of AI as a translator. A transformer-based model (like BERT or OpenAI’s embedding model) takes text, images, or other data and turns them into numbers (vectors). These vectors capture meaning and context, not just words. - Step 2: Storing Vectors in a Vector Database
Instead of saving plain text like a traditional database, a vector database organizes and indexes these vectors. It uses fast-searching algorithms (like Approximate Nearest Neighbor or ANN) to quickly retrieve results when needed. - Step 3: Converting Search Queries into Vectors
When a user types a search query, the system converts it into a vector, just like it did for stored data. This way, it can compare the search based on meaning, not just exact words. - Step 4: Finding the Most Relevant Matches
The database compares the query vector with stored vectors using similarity measures like cosine similarity or locality-sensitive hashing (LSH). The closer the vectors, the more relevant the result.
Why This Matters
This method makes semantic search far more powerful than keyword-based search. Instead of just matching words, it understands intent and context, delivering results that are more accurate, intuitive, and user-friendly.
What Makes Vector Databases Special?
Vector databases aren’t just storage systems—they optimize the entire search process.
- Fast Search with ANN Indexing: Searching millions of vectors one by one would be slow. HNSW and ANN techniques enable instant retrieval.
- Scalability: Vector databases efficiently handle millions to billions of vectors. Cloud solutions like Pinecone and Weaviate ensure seamless performance.
- Multi-Modal Data: Beyond text, vector databases store image, video, and audio embeddings, enabling image and voice-based search.
- Better Search Accuracy: Semantic disambiguation ensures intent-based results. Searching “comfortable chairs for long work hours” returns ergonomic chairs, even without exact phrasing.
- Enterprise Knowledge Management: Businesses organize and retrieve internal documents by meaning, helping employees find reports without exact filenames.
Core Concepts of Semantic Search: How It Works and Why It Matters
Searching for “best smartphone for photography” in a traditional search engine may miss a page describing “top-rated camera phones with high-resolution sensors.” Keyword-based search lacks understanding, while semantic vector search captures intent, delivering more accurate results.
But how does it work? Let’s break it down.
Semantic Search vs. Keyword-Based Search
Before semantic search, most systems relied on full-text search—which simply matches words in a query with words in a document.
The Problem?
- Lacks context understanding (e.g., “Apple” the fruit vs. the company).
- Struggles with synonyms and rephrased sentences.
Semantic Search Fixes This
- Focuses on meaning, not just words.
- Uses embedding-based retrieval to convert text into vectors.
- Similar vectors (e.g., “Best smartphone for photography” and “Top-rated camera phone”) are matched, even without exact words.
Example:
A semantic search engine knows that “best smartphone for photography” and “top-rated camera phone” mean the same thing—even if the words don’t match perfectly.
Understanding Embeddings and Vector Similarity
At the core of semantic search is a concept called semantic embeddings.
What Are Embeddings?
- They are numerical representations of words, sentences, or documents that help AI understand relationships between different terms.
- Think of it like a map of words, where similar ideas are placed closer together and unrelated ideas are farther apart.
For example:
- “dog” and “puppy” would be close together in vector space.
- “dog” and “car” would be far apart.
When a search engine needs to find relevant results, it compares how close two vectors are.
Cosine similarity is one of the most common ways to measure this. It calculates the angle between two vectors—the smaller the angle, the more similar the meanings. If two sentences have high cosine similarity, they are likely talking about the same thing, even if they don’t use the same words.
How Vector Databases Enhance Semantic Search
Handling millions of vectors efficiently is a challenge. Instead of scanning through every single vector, vector databases use advanced indexing techniques to find similar meanings faster.
Key Technologies That Speed Up Semantic Search:
- Approximate Nearest Neighbor (ANN) – Finds similar vectors quickly without checking every single one.
- HNSW Indexing (Hierarchical Navigable Small World) – Organizes vectors into a graph, so related data is easier to retrieve.
- Locality Sensitive Hashing (LSH) – Groups similar vectors into buckets, reducing search time significantly.
Why This Matters for Businesses:
These techniques make semantic search scalable, allowing businesses to quickly retrieve the most relevant results—whether for e-commerce recommendations, customer support, enterprise search, or AI-driven chatbots.
Building Blocks of a Semantic Search System
Now that we understand semantic vector search, let’s explore its key components. A powerful system must be fast, scalable, and accurate, requiring multiple building blocks working together. Let’s go step by step.
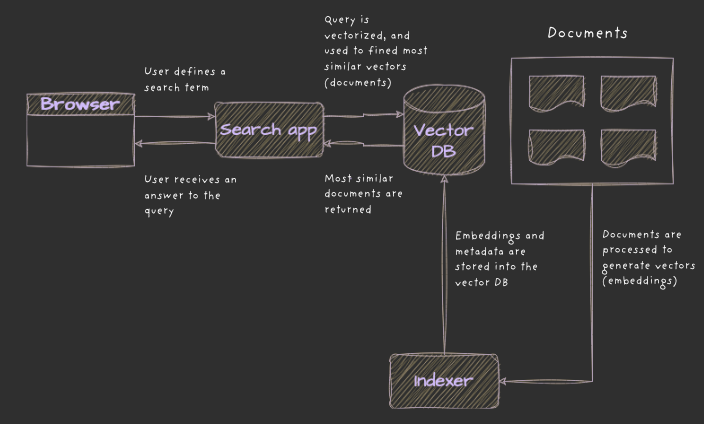
Data Ingestion: Preparing Information for Search
Before we can search for anything, we need data. This can be:
- Text documents (articles, product descriptions, FAQs)
- Structured data (database records, customer support logs)
- Multimedia content (images, audio, videos)
Each piece of data needs to be cleaned and preprocessed before it can be used.
Text Preprocessing Steps
- Remove noise (HTML tags, special characters)
- Standardize text (lowercase, remove stop words)
- Tokenization (split text into words or phrases)
- Lemmatization (convert words to their root form, e.g., “running” → “run”)
The goal? Convert raw data into a format that can be turned into embeddings.
Generating Semantic Embeddings
Once the text is clean, we need to convert it into numerical representations. This is where transformer-based models like BERT, OpenAI embeddings, or Sentence Transformers come in.
How it works:
- The model reads the text and transforms it into a high-dimensional vector.
- Similar sentences get similar vector representations.
For example:
- “Best budget smartphone” → [0.23, 1.57, -0.45, …]
- “Affordable mobile phone” → [0.21, 1.55, -0.47, …]
Even though the wording is different, their vectors are close together, meaning they are contextually similar.
Storing Embeddings in a Vector Database
With thousands or even millions of semantic embeddings, we need a place to store them. This is where vector databases come in.
Vector Database Benefits:
- Stores embeddings efficiently.
- Retrieves results instantly using approximate nearest neighbor (ANN) algorithms.
- Scales to billions of vectors.
Storing embeddings in a vector database ensures lightning-fast searches—even across massive datasets.
Query Processing: Transforming User Input into Vectors
Now, let’s talk about what happens when a user searches for something.
- The search query (e.g., “best shoes for marathon running”) is converted into a vector using the same embedding model used during data ingestion.
- This query vector is sent to the vector database.
- The system looks for the most similar vectors using techniques like cosine similarity or locality sensitive hashing (LSH).
Instead of searching for exact keyword matches, it finds the closest meanings.
For example, if a user searches for “comfortable office chair”, the system might return results for:
- “ergonomic desk chair”
- “lumbar support chair for long work hours”
Because their vectors are similar, they are highly relevant results—even though they don’t share exact words.
Indexing for Faster Search (ANN and HNSW Indexing)
Searching millions of vectors one by one is not practical. That’s why vector databases use indexing techniques to speed things up.
- Approximate Nearest Neighbor (ANN) – Instead of scanning every vector, it narrows down the search space to only the most relevant ones.
- HNSW Indexing (Hierarchical Navigable Small World) – A graph-based indexing method organizes vectors into layers for quick retrieval.
Ranking & Refining Search Results
Once we retrieve similar vectors, how do we rank them?
- Cosine similarity is used to measure relevance—higher scores mean better matches.
- Some systems use hybrid ranking—combining semantic embeddings with keyword-based filters for even better accuracy.
- Advanced models apply RAG (Retrieval-Augmented Generation) to summarize or refine answers dynamically.
This final step ensures the most relevant results appear at the top—giving users exactly what they need.
Caching for Faster Performance
The system performs vector transformations, and ANN searches every time a user searches.
To speed things up, we can cache popular queries.
How to Cache Semantic Search?
- Store frequently searched vectors in an in-memory database like Redis.
- Reduce unnecessary recomputations by keeping precomputed embeddings for common queries.
- Implement time-based expiration to keep results fresh.
Caching improves performance dramatically, ensuring users get results in milliseconds.
How to Cache Semantic Search for Faster and Smarter Results
Semantic search is incredibly powerful because it understands intent, context, and meaning—not just keywords. But this advanced processing comes with a challenge: every search query requires generating and comparing high-dimensional vectors, which can slow things down, especially when handling thousands of searches per second. This can lead to latency issues and high computational costs, making real-time performance difficult to maintain.
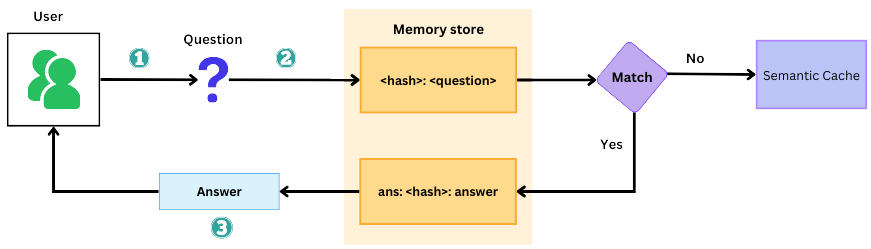
The solution? Caching.
By storing frequently searched results, caching dramatically speeds up response times, reduces redundant computations, and lowers database and API costs, making the entire system faster, more efficient, and cost-effective. Let’s explore how it works.
Why Caching is Crucial for Semantic Search
Traditional search uses indexing and keyword caching for speed, while semantic search relies on deep learning, vector embeddings, and ANN searches, which are costly. Caching frequent queries avoids reprocessing, enabling instant results without regenerating embeddings or full searches.
Caching helps in two major ways:
- Query-Level Caching – Store full query results for frequently asked questions.
- Embedding-Level Caching – Store embeddings for common queries, reducing the need to regenerate them.
Query-Level Caching: Storing Entire Search Results
If users often search for similar things, it makes sense to cache their search results.
How it works:
- Query Processing: “Best laptop for video editing” retrieves results from the vector database.
- Caching: The query and top results are stored (e.g., Redis, Memcached).
- Faster Retrieval: The next time someone searches for “best laptop for video editing”, the system skips vector retrieval and directly serves results from the cache.
Best for:
- FAQs, customer support, e-commerce searches.
- Static content with infrequent changes.
Limitations:
- Cached results may become outdated with new content.
- Ineffective for dynamic, user-specific searches.
Solution: Implement cache expiration for periodic updates.
Embedding-Level Caching: Storing Query Vectors
Sometimes, users phrase things slightly differently, but they mean the same thing.
Example:
- “Affordable gaming laptop” and “Best budget gaming laptop” mean the same thing.
- Their semantic embeddings are almost identical.
- Instead of regenerating embeddings for each variation, we cache them.
How it works:
- Convert the user query into a vector embedding.
- Check if the embedding already exists in the cache.
- If found, retrieve precomputed search results.
- If not found, compute embedding, retrieve results, and store them for future use.
Best for:
- Semantic disambiguation (similar meaning, different queries).
- Reducing API calls to embedding models (OpenAI, Hugging Face).
Limitations:
- Needs vector-based similarity matching in the cache.
- More complex than query-level caching.
Solution: Use vector search caching in Redis or FAISS for fast lookups.
Using Redis for Semantic Search Caching
Redis is a great caching tool because it supports Key-value storage (for query-level caching) and Vector storage (using Redis’s ANN module for fast retrieval).
Implementation Steps:
- Store query results in Redis with a time-to-live (TTL) expiration.
- Cache embeddings and precomputed search results for frequent queries.
- Use locality sensitive hashing (LSH) or HNSW indexing in Redis for fast vector similarity search.
Example: Query-Level Caching in Redis
|python
import redis
import json
# Connect to Redis
cache = redis.Redis(host='localhost', port=6379, db=0)
# Function to store query results
def store_in_cache(query, results, expiration=3600): # 1-hour TTL
cache.set(query, json.dumps(results), ex=expiration)
# Function to retrieve cached results
def get_from_cache(query):
cached_results = cache.get(query)
return json.loads(cached_results) if cached_results else NoneExample: Embedding-Level Caching in Redis
|python
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Function to store embeddings in cache
def store_embedding(query, embedding):
cache.set(query, json.dumps(embedding.tolist()), ex=3600)
# Function to retrieve embeddings from cache
def get_embedding(query):
cached_embedding = cache.get(query)
return np.array(json.loads(cached_embedding)) if cached_embedding else NoneWith this setup, Redis stores and retrieves both search results and query embeddings—reducing response times significantly.
Hybrid Caching: Combining Multiple Caching Strategies
For optimal performance, combine query-level caching for exact matches, embedding-level caching for similar queries, and partial result caching for long queries.
Example: Hybrid Caching Workflow
- Check if the exact query exists in the cache (query-level caching).
- If not, check if a similar query embedding exists (embedding-level caching).
- If neither exist, compute everything from scratch, retrieve results, and store them in the cache for future use.
Keeping Cached Data Fresh
Caching is useful, but stale data is an issue.
Best Practices:
- Time-Based Expiration: Set TTL to refresh old results.
- Content-Aware Expiration: Invalidate cache when new content is added.
- Adaptive Caching: Retain high-traffic queries longer and remove low-demand ones faster.
Example: Automatic Cache Expiration
|python
# Set TTL for cached search results (auto-refresh after 1 day)
cache.set("popular_search", json.dumps(results), ex=86400)Practical Use Cases of Semantic Search and Vector Databases
Semantic search isn’t just a cool technology—it’s solving real daily business problems. Businesses use semantic vector search for smarter, faster, and more intuitive search experiences. Let’s see how various industries benefit from vector databases and embedding-based retrieval.
E-Commerce: Smarter Product Search & Recommendations
Traditional searches struggle with synonyms, leading to missed results.
Semantic Search:
- Understands intent, retrieving relevant products.
- Matches reworded queries for accurate results.
- Enables similarity-based recommendations.
Example: Searching “waterproof travel backpack” retrieves “weather-resistant hiking backpack” via embedding-based retrieval and ANN search.
Customer Support: AI-Powered Chatbots & Help Desks
Keyword-based search often fails to return relevant help articles.
Semantic Search:
- Chatbots understand natural language for better answers.
- Find relevant solutions without exact keyword matches.
- Enhances conversational search.
Example: “I can’t log in” retrieves “Reset password” and “Troubleshooting login issues” using transformer-based embeddings and cosine similarity.
Enterprise Knowledge Management: Smarter Internal Search
Employees struggle to find relevant reports and documents.
Semantic Search:
- Retrieves files by meaning, not just file names.
- Supports multilingual search.
- Allows filtering by relevance or department.
Example: “Remote work policy update” retrieves “2024 Work-from-Home Guidelines” using vector embeddings and HNSW indexing.
Healthcare & Medical Research: Faster Information Access
Medical databases return incomplete or irrelevant keyword-based results.
Semantic Search:
- Finds clinical trials and research instantly.
- Recognizes medical synonyms (“hypertension” = “high blood pressure”).
- Improves diagnoses and treatment recommendations.
Example: “Studies on Type 2 diabetes” retrieves “Metformin efficacy” using domain-specific embeddings and LSH for fast search.
Media & Content Discovery: Personalized Recommendations
Keyword-based search fails to recommend similar content.
Semantic Search:
- Suggest content based on themes, not just words.
- Uses vector similarity for recommendations.
- Adapts to user behavior.
Example: “Movies like Inception” suggests “Interstellar” and “Shutter Island” using cosine similarity on movie embeddings.
Cybersecurity & Fraud Detection: Identifying Anomalies
Rule-based systems miss evolving fraud patterns.
Semantic Search:
- Detects unusual transactions based on similarity to fraud cases.
- Flags high-risk activities without predefined rules.
- Learns and adapts to new fraud techniques.
Example: Banks detect “unusual transaction sequences” and “high-risk patterns” using vector-based anomaly detection and RAG models.
Semantic vector search enhances search accuracy, personalization, and fraud detection, making it essential across industries.
Tips for Implementation: Best Practices for Semantic Search
Semantic vector search requires the right tools, efficient data processing, and an optimized system. Developers aim for speed, scalability, and accuracy while minimizing costs. Here are the key steps and best practices.
Choose the Right Embedding Model
The foundation of semantic search is the embedding model. It converts text, images, or documents into high-dimensional vectors that capture meaning.
- BERT-based models – Ideal for general-purpose semantic search.
- Sentence Transformers (e.g., all-MiniLM-L6-v2) – Lightweight and optimized for fast vector processing.
- OpenAI Embeddings (text-embedding-ada-002) – Best for API-based implementations.
- Custom Transformer Models – Fine-tuned for domain-specific use cases (e.g., healthcare, finance).
Best Practice:
- If performance is a priority, use a smaller, optimized model like all-MiniLM-L6-v2.
- If accuracy is more important, consider larger models like BERT or fine-tune a domain-specific transformer-based model.
Store Vectors in a Vector Database
Traditional relational databases aren’t optimized for vector search. Storing embeddings in a vector database ensures fast, scalable retrieval.
Best Practice:
- Choose a fully managed service (e.g., Pinecone) if you don’t want to manage infrastructure.
- If you need complete control, go with an open-source solution like Weaviate or Milvus.
Use Efficient Indexing for Fast Retrieval
Searching millions of embeddings is slow. ANN (Approximate Nearest Neighbor) indexing speeds up queries by narrowing the search space.
- HNSW (Hierarchical Navigable Small World) – Best for large-scale search with low latency.
- IVF (Inverted File Indexing) – Good for batch processing and efficient memory usage.
- LSH (Locality Sensitive Hashing) – Faster but slightly less accurate than HNSW.
Best Practice: Use HNSW for fast retrieval or IVF for a balance of speed and memory efficiency.
Optimize Query Performance with Caching
- Every time a user searches, the system needs to:
- Convert the query into an embedding.
- Compare it against millions of stored vectors.
- Retrieve the most similar results.
Best Practice: Use hybrid caching, store full results for frequent queries, and cache embeddings for semantic similarity lookups.
Fine-Tune Ranking for Better Search Results
Not all retrieved vectors are equally relevant. Improve ranking by using re-ranking models to refine search result order.
Ranking Methods:
- Cosine Similarity: Simple and effective for vector matching.
- Hybrid Ranking: Combines vector similarity with keywords for accuracy.
- ML Re-ranking: Fine-tunes results using domain-specific data.
Best Practice: If results seem off, consider re-ranking with a fine-tuned model to prioritize more relevant answers.
Enable Multilingual Semantic Search
If your business operates globally, you need to support multiple languages.
How to Implement Multilingual Search:
- Use a multilingual embedding model (e.g., XLM-R).
- Store language-agnostic embeddings and convert queries into the same semantic space for cross-language search.
Best Practice: Use multilingual transformer-based models to ensure consistent search quality across languages.
Handle Enterprise-Scale Deployments
You need a scalable architecture for large-scale applications that can handle millions of queries per second.
Scaling Best Practices:
- Use distributed vector databases (Weaviate, Milvus) for high-throughput search.
- Scale with cloud solutions (Pinecone, SingleStore).
- Implement sharding to distribute vector storage across multiple servers.
- Implement sharding and leverage GPU acceleration for real-time performance.
Debug and Monitor Search Performance
Like any AI-powered system, semantic search needs constant monitoring.
Best Practices for Monitoring & Debugging:
- Track Latency: Ensure real-time search performance.
- Analyze Relevance: Log user interactions to refine ranking.
- Monitor Vector Drift: Re-train models as data evolves.
- A/B Testing: Optimize embeddings and ranking techniques.
Conclusion
Semantic search is changing the way we find information, making traditional keyword-based searches feel outdated. By using vector databases, businesses can deliver faster, more accurate, and smarter search experiences—leading to better product recommendations, improved customer support, enhanced knowledge management, and even real-time multilingual search.
To make the most of it, companies need to choose the right vector database (such as Pinecone, Weaviate, or Milvus), fine-tune embeddings and indexing methods (like HNSW, LSH, or ANN), and use efficient caching to keep search lightning-fast. As AI-powered search continues to evolve, we can expect even bigger innovations, including multimodal search and highly personalized AI assistants, making information access smarter, more intuitive, and seamlessly integrated into everyday life.




