
Have you ever searched for something online, made a small typo, and still found exactly what you were looking for? That’s the magic of fuzzy search at work!
Search engines don’t always need an exact match to understand what you mean. Instead, they can intelligently guess the right results — even if you misspell a word or use a slightly different phrase. This is especially useful for businesses where customers might type in product names, technical terms, or brand names incorrectly.
Fuzzy search helps improve accuracy, reduce frustration, and ensure users get relevant results without needing perfect spelling. Whether it’s an e-commerce store, a corporate knowledge base, or a customer support chatbot, implementing fuzzy matching can make search smarter and more user-friendly.
Want to know how it works in Elasticsearch and OpenSearch? Let’s dive in!
Table of contents
- Why Fuzzy Search Matters for Businesses Success
- Core Concepts Behind Fuzzy Matching
- Implementing Fuzzy Search in Elasticsearch and OpenSearch
- Real-World Use Cases of Fuzzy Search: Making Search Smarter Across Industries
- Developer Insights: Building an Efficient Fuzzy Search System
- Advanced Features and Tuning for Fuzzy Search
- Conclusion
Why Fuzzy Search Matters for Businesses Success
Think about it:
- A customer types “iphon 15” instead of “iPhone 15” in your e-commerce store. Should they see “No Results Found”? Of course not!
- A user searches for “receipts” but means “recipes” on a food website. The system should still return relevant results.
- A developer needs to search error logs but makes a small typo—should they miss critical data because of that? No way!
Fuzzy search helps businesses reduce lost opportunities, improve user experience, and boost conversions.
How Fuzzy Search Works?
It relies on approximate string matching—a method that finds words similar to the input, even if they aren’t exact matches. This happens through algorithms like:
- Levenshtein Distance: Measures how many edits (insertions, deletions, substitutions) are needed to turn one word into another.
- Damerau-Levenshtein: Like Levenshtein, but also considers letter swaps (like “form” vs. “from”).
- Phonetic Matching (Soundex): Finds words that sound alike but are spelled differently.
Elasticsearch and OpenSearch offer built-in fuzzy search capabilities, making them popular among businesses needing fast, accurate search results.
Core Concepts Behind Fuzzy Matching
Ever typed something wrong in a search bar but still got the right results? That’s fuzzy matching in action! It helps search engines find relevant results even when users make typos, mix up letters, or use different word variations.
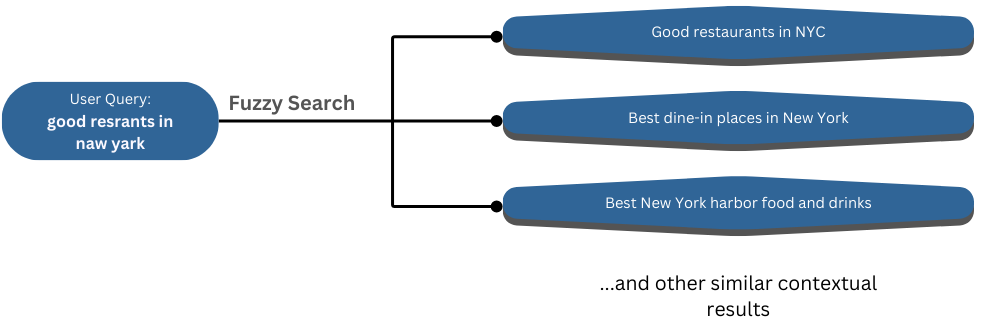
The result? More accurate searches, fewer frustrated users, and a smoother experience. Whether you’re running an online store, a website search, or a developer-friendly query system, fuzzy search in Elasticsearch and OpenSearch makes sure users find what they need—even if they don’t type it perfectly.
But how does it actually work? Let’s break it down.
How Fuzzy Search Works: The Power of Approximate Matching
Ever misspelled a word in search but still got the right result? That’s fuzzy matching in action! Instead of requiring exact matches, fuzzy search finds words that are similar, even if they’re typed incorrectly.
Imagine you search for “Macbok Pro”—a regular search engine might return nothing because that exact phrase doesn’t exist. But fuzzy matching recognizes the mistake and understands that you probably meant “MacBook Pro” instead.
So how does it work? Let’s break it down..
Levenshtein Distance: Measuring Edits Between Words
Fuzzy matching is based on a concept called approximate string matching, which compares words and calculates how similar they are. One of the most common methods is Levenshtein distance—which counts how many tiny edits it takes to turn one word into another.
Each edit includes:
- Insertion: Adding a letter (e.g., “phon” → “phone”)
- Deletion: Removing a letter (e.g., “appple” → “apple”)
- Substitution: Replacing a letter (e.g., “carr” → “cart”)
For example:
- The Levenshtein distance between “hello” and “hallo” is 1 (only one letter needs to be changed).
- The distance between “kitten” and “sitting” is 3 (kitten → sitten → sittin → sitting).
Elasticsearch and OpenSearch allow searches to return results even when the input differs slightly from stored data.
Damerau-Levenshtein: A Smarter Version
Sometimes, typos aren’t just missing or wrong letters—they involve swapped letters. That’s where Damerau-Levenshtein distance comes in.
Example:
- “form” vs. “from” → Only one swap is needed
- “sotfware” vs. “software” → A simple letter swap
Why It Matters: This method is ideal for real-world typing mistakes, like when someone types “adnroid” instead of “android”. Elasticsearch’s fuzzy query can handle these errors, making searches more forgiving and flexible.
Phonetic Matching (Soundex): Finding Words That Sound Alike
Sometimes, search users don’t just mistype words—they spell them the way they sound.
That’s where phonetic matching (Soundex) comes in. It helps find words that sound similar but are spelled differently.
Example:
- “Jon” and “John”
- “Katherine” and “Catherine”
- “disk” and “disc”
Why It Matters: Elasticsearch and OpenSearch can integrate phonetic matching to improve name searches, product lookups, and business directories, ensuring that similar-sounding words match.
Thresholds in Fuzzy Matching: Controlling Accuracy
Fuzzy matching isn’t always one-size-fits-all. Sometimes, a business needs loose matching (allowing more errors), and sometimes, it needs strict matching (fewer errors allowed).
Example:
- Strict Matching: “Samsung Galaxy S21” won’t match “Samsung Galaxy S20”.
- Loose Matching: “iPone” will still match “iPhone”.
Why It Matters: Elasticsearch and OpenSearch allow businesses to adjust these settings, balancing accuracy and flexibility based on user needs.
How Fuzzy Matching Enhances Business Search
- E-Commerce: Customers find products even with typos (e.g., “bluetooth haedphones” → “Bluetooth headphones”).
- Website Internal Search: Employees can locate internal documents even with slight keyword variations.
- Developer Perspective: Fuzzy search in logs ensures that small typos don’t prevent critical error tracking.
- Fuzzy matching ensures that every search counts—reducing frustration and improving user satisfaction.
Implementing Fuzzy Search in Elasticsearch and OpenSearch
Ever typed a search with a small typo and still got the right result? That’s fuzzy search in Elasticsearch at work! It helps users find what they’re looking for, even if they misspell words, make typing mistakes, or use different variations of a term.
Instead of returning zero results when a word isn’t an exact match, Elasticsearch intelligently finds the closest matches—making search more flexible, accurate, and user-friendly.
Now, let’s break down how to implement fuzzy search in Elasticsearch step by step.
1 .Setting Up an Elasticsearch Index for Fuzzy Search
First, create an index with a text field that allows fuzzy matching.
Run this command to create an index:
|json
PUT /products
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "custom_analyzer"
}
}
}
}This sets up a case-insensitive search by converting all text to lowercase.
2. Indexing Sample Data
Next, let’s add some product names to our index.
|json
POST /products/_doc/1
{
"name": "Wireless Bluetooth Headphones"
}
POST /products/_doc/2
{
"name": "Noise Cancelling Headphones"
}
POST /products/_doc/3
{
"name": "Bluetooth Earbuds"
}These documents are now searchable within Elasticsearch.
3. Performing a Basic Fuzzy Search Query
Now, let’s test fuzzy search by searching for “Bluetoth” (a misspelling of “Bluetooth”).
|json
GET /products/_search
{
"query": {
"match": {
"name": {
"query": "Bluetoth",
"fuzziness": "AUTO"
}
}
}
}Expected result? Elasticsearch understands that “Bluetoth” is close to “Bluetooth” and returns relevant results.
4. Adjusting Fuzziness Levels
Elasticsearch lets you control fuzziness levels, allowing more or fewer mistakes in search queries.
Using Different Fuzziness Values
“AUTO” (Default)
Automatically sets fuzziness based on word length.
- Short words (1-2 letters) → No fuzziness
- Medium words (3-5 letters) → One-character difference allowed
- Long words (6+ letters) → Two-character difference allowed
Fixed Values (“1” or “2”)
- Fuzziness: 1 → Allows one-character difference (e.g., “Earbus” → “Earbuds”)
- Fuzziness: 2 → Allows two-character differences (e.g., “Bluetoth” → “Bluetooth”)
Manually set the number of allowed character changes.
|json
GET /products/_search
{
"query": {
"match": {
"name": {
"query": "Bluetoth",
"fuzziness": 2
}
}
}
}This query allows up to two character differences, making results even more flexible.
5. Using Fuzzy Matching with Multiple Fields
Sometimes, businesses want to search across multiple fields (e.g., product name, description, and category).
|json
GET /products/_search
{
"query": {
"multi_match": {
"query": "Bluetoth",
"fields": ["name", "description", "category"],
"fuzziness": "AUTO"
}
}
}This expands fuzzy search beyond a single field, improving search accuracy.
6. Boosting Relevant Matches
What if you want to prioritize exact matches over fuzzy ones? You can use “tie_breaker” to favor exact matches while still allowing fuzzy ones.
|json
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": {
"query": "Bluetooth",
"boost": 2
}
}
},
{
"match": {
"name": {
"query": "Bluetoth",
"fuzziness": "AUTO"
}
}
}
]
}
}
}Impact?
- If a user types “Bluetooth” correctly, those results rank higher.
- If they type “Bluetoth”, fuzzy matching still works, but exact matches take priority
7. Optimizing Fuzzy Search Performance
Fuzzy search can be resource-intensive, so here’s how to optimize it:
- Use Shorter Fields → Fuzzy matching works best on single words or short phrases.
- Avoid Fuzzy Search for Common Terms → Common words like “the” or “and” don’t need fuzzy logic.
- Use Keyword Fields for Exact Matches → For some data (e.g., product SKUs), turn off fuzziness.
- Limit Fuzziness → Avoid excessive fuzziness (fuzziness: 2 is usually enough).
OpenSearch vs. Elasticsearch: A Comparative Overview
| Feature | Elasticsearch | OpenSearch |
| Origin | Developed by Elastic | Forked from Elasticsearch 7.10.2 by AWS |
| License | Dual license: Server-Side Public License (SSPL) & Elastic License (proprietary) | Fully open-source under Apache 2.0 license |
| Ownership & Development | Controlled by Elastic, with proprietary feature additions | Community-driven, led by AWS with open-source contributions |
| Core Features | Advanced search, analytics, machine learning, security features | Like Elasticsearch 7.10.2 but evolving independently |
| Machine Learning | Available as a proprietary feature in Elastic’s paid version | Limited; currently relies on third-party or custom solutions |
| Security Features | Available in paid versions (Elastic Security, role-based access control) | Fully open-source security features (RBAC, authentication, encryption) |
| Visualization Tools | Kibana (Elastic’s visualization tool) | OpenSearch Dashboards (forked from Kibana) |
| Community & Support | Enterprise support available via Elastic | Community-driven with AWS and open-source backing |
| Performance & Scalability | Advanced performance optimizations, scaling suited for enterprise needs | Similar performance to Elasticsearch 7.10.2, growing with community enhancements |
| Ecosystem & Integrations | Works with Elastic Stack (Logstash, Beats, Kibana) | Works with OpenSearch Dashboards and community plugins |
| Best For | Enterprises needing commercial support and proprietary features | Organizations wanting a fully open-source, community-driven alternative |
Real-World Use Cases of Fuzzy Search: Making Search Smarter Across Industries
Fuzzy search isn’t just a nice-to-have—it’s essential for businesses that rely on accurate, user-friendly search experiences. Whether it’s helping customers find products, improving internal search, or enhancing chatbot responses, fuzzy matching ensures typos and misspellings don’t block access to critical information.
Let’s explore how different industries use fuzzy search to solve real-world problems.
E-Commerce: Helping Customers Find Products Easily
Customers don’t always type product names perfectly. Typos, misspellings, or different spellings happen all the time.
Example: A customer searching for “wirless mouse” instead of “wireless mouse” still gets relevant results.
How it works:
- Fuzzy search in Elasticsearch or OpenSearch detects the misspelled word.
- It matches similar words using Levenshtein distance.
- The correct product appears in search results, preventing lost sales.
Result: Better user experience, fewer abandoned searches, and higher conversion rates.
Website Internal Search:
Companies store thousands of documents, but employees struggle to find the right files if search terms aren’t exact.
Example: An HR team searching for “employee benifits” (instead of “employee benefits”) still gets relevant documents.
How it works:
- Fuzzy search corrects spelling mistakes.
- It matches related terms, improving document discovery.
- Employees find what they need without frustration.
Result: More efficient knowledge management, saving time and effort.
Customer Support: Improving Chatbot and Help Desk Responses
Customers often describe their issues differently. Chatbots and help centers must understand similar phrases and common typos.
Example: A customer types “refund statis” instead of “refund status”, but the chatbot still provides the correct response.
How it works:
- Fuzzy matching detects variations in words.
- Phonetic matching (Soundex) recognizes different pronunciations.
- The system delivers the correct support article or automated reply.
Result: Better chatbot performance, fewer support tickets, and improved customer satisfaction.
Healthcare: Matching Patient Records Accurately
Hospitals and clinics manage large databases of patient records. A small spelling mistake in a patient’s name could lead to missing critical information.
Example: A doctor searching for “Samantha Rodreguez” instead of “Samantha Rodriguez” still finds the correct medical history.
How it works:
- Fuzzy search corrects minor errors in patient names.
- Multi-field matching ensures accurate records retrieval.
- Critical health records stay accessible, even with variations.
Result: More accurate patient data management, avoiding misdiagnoses or treatment delays.
Travel & Hospitality: Smart Destination & Booking Searches
Users often misspell destinations when booking flights, hotels, or vacation packages. Fuzzy search ensures they still find what they’re looking for.
Example: A traveler types “San Fransico” instead of “San Francisco” but still sees relevant flights and hotels.
How it works:
- Phonetic matching (Soundex) corrects misspellings.
- Fuzzy search ensures travelers don’t hit dead ends when searching.
Result: Higher booking completion rates and better customer experience.
Fuzzy search is not just about fixing typos—it’s about creating a seamless search experience that ensures users always find what they need. From e-commerce to healthcare to travel, fuzzy search prevents lost opportunities, boosts customer satisfaction, and keeps businesses running smoothly.
Developer Insights: Building an Efficient Fuzzy Search System
Implementing fuzzy search in Elasticsearch or OpenSearch is all about striking the right balance between performance, accuracy, and user experience. While fuzzy search helps users find what they need—even with typos or variations — developers must fine-tune it to ensure searches remain fast and relevant.
By carefully managing these elements, developers can create a search experience that feels intuitive, responsive, and highly relevant—without sacrificing speed or efficiency.
Performance vs. Accuracy – The Trade-Off
Fuzzy search is powerful, but it comes at a cost. Every fuzzy query requires more processing power than an exact match.
- More flexibility = more CPU and memory usage.
- Less flexibility = faster searches but fewer matches.
Solution: Fine-tune fuzziness settings for the right balance.
- Keep fuzziness at AUTO for best performance.
- Limit searches to specific fields instead of the entire document.
- Use caching and pre-filtering to reduce overhead.
Choosing the Right Algorithm for Fuzzy Matching
Different scenarios require different matching techniques.
- Levenshtein Distance – Most common. Counts insertions, deletions, and substitutions.
- Damerau-Levenshtein – Also considers adjacent letter swaps. More flexible.
- Phonetic Matching (Soundex, Metaphone) – Great for names and spoken-word searches.
Best practice: Use Levenshtein for typos, Damerau-Levenshtein for human errors, and Phonetic Matching for name-based searches.
Indexing Strategies – How to Optimize for Fuzzy Search
A well-structured index can make or break performance.
- Use an Edge N-Gram tokenizer to speed up partial word matches.
- Set the right analyzer – Custom analyzers improve results for specific use cases.
- Preprocess common errors (like replacing ph with f) to reduce processing time.
Example – Custom Analyzer in Elasticsearch:
json|
{
"settings": {
"analysis": {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "edge_ngram_filter"]
}
}
}
}
}This improves partial matching for search queries, reducing the need for full fuzzy searches.
Handling Large Datasets – Keeping Queries Fast
Fuzzy search slows down as datasets grow. Best practices for large-scale searches:
- Use pre-indexed synonyms for common misspellings instead of relying on fuzzy logic.
- Limit fuzziness distance to 1 or 2 to prevent unnecessary computations.
- Enable sharding in Elasticsearch or partitioning in OpenSearch for better scalability.
Use case:
E-commerce sites with millions of products benefit from a hybrid approach:
Exact matches first → Synonyms second → Fuzzy search as a last resort.
Real-Time vs. Batch Processing – When to Use Each
Do you need instant results, or is a preprocessed approach better?
Real-time fuzzy search – Needed for interactive search, like user input corrections.
Batch fuzzy processing – Works better for duplicate detection (e.g., finding similar customer records).
Recommendation:
For websites, keep fuzzy searches real-time.
For large databases, run batch fuzzy matching in the background.
Fine-Tuning Fuzziness for Best User Experience
Users expect accurate results—but not at the cost of performance.
How to fine-tune?
- Use fuzziness: AUTO for dynamic adjustments.
- Apply prefix_length to ignore minor differences at the start of words.
- Set query boosts to favor exact matches over fuzzy ones.
Example – Optimized Fuzzy Query in Elasticsearch:
json|
{
"query": {
"match": {
"product_name": {
"query": "wirless mouse",
"fuzziness": "AUTO",
"prefix_length": 2,
"boost": 2
}
}
}
}This prioritizes close matches while keeping searches efficient.
Advanced Features and Tuning for Fuzzy Search
Fuzzy search is great for helping users find the right results, even when they make typos or use different word variations. But as datasets grow larger, search speed can slow down, affecting user experience. This is where advanced tuning techniques come in.
By using n-grams, edge n-grams, and hybrid search approaches, developers can optimize performance, improve accuracy, and enhance search recall—without sacrificing speed. Let’s explore how these techniques make fuzzy search faster and smarter.
Enhancing Search Speed with N-Grams and Edge N-Grams
One major challenge with fuzzy matching is that it can slow down significantly when dealing with large datasets. Each fuzzy query requires multiple calculations to compare words and find the best matches, which can be computationally expensive.
Solution: Use n-grams and edge n-grams to pre-process words.
How it helps:
- Breaks words into smaller segments.
- Allows faster approximate matching.
- Reduces the need for computationally expensive fuzzy queries.
Example – Edge N-Gram Tokenizer in Elasticsearch:
json|
{
"query": {
"match": {
"product_name": {
"query": "bluetooth headphons",
"fuzziness": "1",
"prefix_length": 2,
"max_expansions": 50
}
}
}
}Hybrid Search – Combining Exact, Fuzzy, and Synonyms
While fuzzy search is powerful, relying on it alone isn’t always the best approach. Sometimes, an exact match is available, or users search using synonyms that the system doesn’t recognize.
Solution: Combine exact matching, fuzzy search, and synonyms to increase recall without compromising precision.
Hybrid Approach for Best Results:
- Step 1: Look for exact matches first.
- Step 2: If no match, try fuzzy search.
- Step 3: Expand search using synonyms or related words.
Example – Hybrid Query:
json|
{
"query": {
"bool": {
"should": [
{ "match": { "product_name": { "query": "wireless mouse", "boost": 3 } } },
{ "match": { "product_name": { "query": "wireless mouse", "fuzziness": "AUTO" } } }
]
}
}
}Conclusion
Fuzzy search brings flexibility to queries, ensuring users find what they need—even with typos or slight variations. In Elasticsearch and OpenSearch, fuzzy matching enhances search accuracy across e-commerce platforms, internal databases, and large-scale data retrieval systems. By intelligently balancing precision and recall, businesses can create faster, more intuitive, and error-tolerant search experiences that improve both user satisfaction and operational efficiency.
Key Takeaways:
- Fine-tune fuzziness to balance precision and recall.
- Enhance exact matches while maintaining search flexibility.
- Leverage phonetic matching & N-grams for smarter results.
- Scale effectively to handle large datasets.
- Optimize fuzzy search for speed and intelligence.
By refining your fuzzy search strategy, you can deliver seamless, user-friendly search experiences that keep customers engaged and information easily accessible.
For more expert insights on search technology and optimization, explore our latest blogs:
- Faceted Search in E-Commerce
- LlamaIndex Document Indexing: Unlock Faster, Smarter Content Retrieval
- BM25 or TF‑IDF? Find Out Which Drives Better Search Results
- Semantic Search: How Vector Databases Transform Information Retrieval
- Lexical vs. Semantic vs. Vector Search
- Why Is WooCommerce Search So Slow? 5 Proven Ways to Speed It Up
- How to Choose the Best Enterprise Search Solution for Business Needs?




